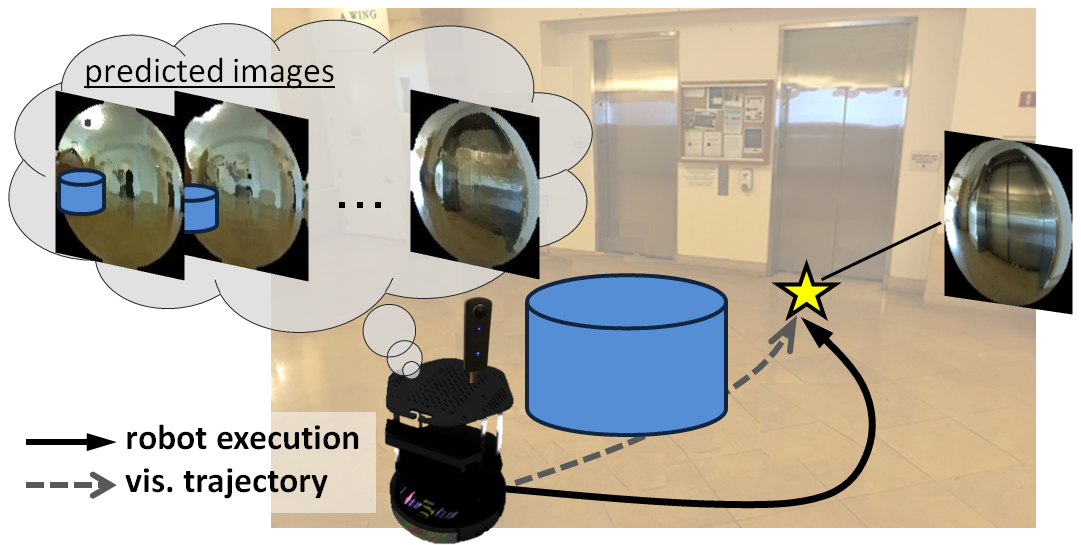
Humans can routinely follow a trajectory defined by a list of images/landmarks. However, traditional robot navigation methods require accurate mapping of the environment, localization, and planning. Moreover, these methods are sensitive to subtle changes in the environment. In this project, we propose a Deep Visual MPC-policy learning method that to follow visual trajectories using only color images while avoiding collisions with objects that are not in the visual trajectory. Our model, PoliNet, takes in as input a visual trajectory (sequence of images prerecorded during another agent's motion) and the image of the robot's current view and outputs velocity commands that optimally balance between trajectory following and obstacle avoidance. PoliNet is trained using a differentiable image predictive model, VUNet-360, an improve version of our prior work VUNet, and a differentiable traversability estimation model, GONet in a MPC setup, with minimal human supervision. After training, PoliNet can be applied to new scenes and new visual trajectories without retraining. We show experimentally that PoliNet allows a robot to follow a visual trajectory even when we change the initial location with respect to the recorded one or in the presence of previously unseen obstacles. We validated our algorithm with tests both in a realistic simulation environment and in the real world. We also show that we can generate visual trajectories in simulation and execute the corresponding path in the real world. Our approach outperforms classical approaches as well as previous learning-based baselines in success rate of goal reaching, sub-goal coverage rate, and computational load.
This video summarizes our approach and shows some of the generated robot behaviors in simulation and in real world:
Predicting future images conditioned on optimal velocities
We use as input for our visual navigation method the front and back images from a 360 camera. Thus, as part of our method, we developed VUNet-360, an extension of our prior differentiable image predictive model VUNet that can propagate information between the front and back images to predict more accurate future images.
In this video we show the current images to the navigating agent (left), the subgoal image (middle), which is the next image from the visual trajectory our method will try to reach, and the 8-th predicted image by VUNet-360 (right). To generate predicted images we feed the 8-next optimal velocities generated by our DVMPC network, PoliNet.
The subgoal images and the predicted images conditioned on PoliNet commands are very similar. This indicates that the commands generated by PoliNet will bring the robot to the desired visual location.
Navigation with PoliNet
We evaluated our method (PoliNet trained with VUNet-360 and GONet) on three types of navigation experiments: sim2sim, real2real and sim2real.
Sim2Sim
In the sim2sim experiments, we evaluate our method in our simulator Gibson Environment. Before the navigation, we collect visual trajectories (sequences of subgoal images) by tele-operating the simulated robot. The environments for the evaluation are completely different to the environments we used for training. Moreover, we include obstacles after we have recorded the visual trajectories. Our method needs to deviate from the visual trajectory to avoid them, returning to the trajectory after overcoming the obstacles. In the following video we show the execution of a visual trajectory without obstacles (left) aand with obstacles (right):
Real2Real
In the real2real experiments, we collect visual trajectories tele-operating the real robot before the navigation. Then, we bring the robot close to the initial location and command it to reproduce the trajectory, based only on the images and without retraining. Although there are environmental changes and/or obstacles that make the visual trajectory different to the current images, our method avoids collisions and arrives at the goal. The following video depicts the robot navigating using PoliNet. In the bottom we include the front and back current images (first two left images), the current image subgoal (middle two images) and the 8th predicted images assuming the execution of the velocities from PoliNet (two most right images).
Long Real2Real Trajectory
This video shows our robot navigating in a much longer real2real experiment:
Sim2Real
In the sim2real experiments, we collect the visual trajectory in our simulator, Gibson Environment, and execute them in the real world. This shows that our method is robust to the sim2real gap. In the video we see the robot navigating and exectuting the visual trajectory generated in the simulator, and in the bottom we include the front and back current images (first two left images), the current image subgoal (middle two images) and the 8th predicted images assuming the execution of the velocities from PoliNet (two most right images):




