Publication
Checkout our paper (under review), arXiv paper, supplementary material, bibtex.

Feel free to contact us for more information.
Appendix
In addition to the original manuscript, we show additional qualitative and quantitative results to verify our proposed approach. (In arXiv paper, we have appendix, which shows following results.)
Qualitative results
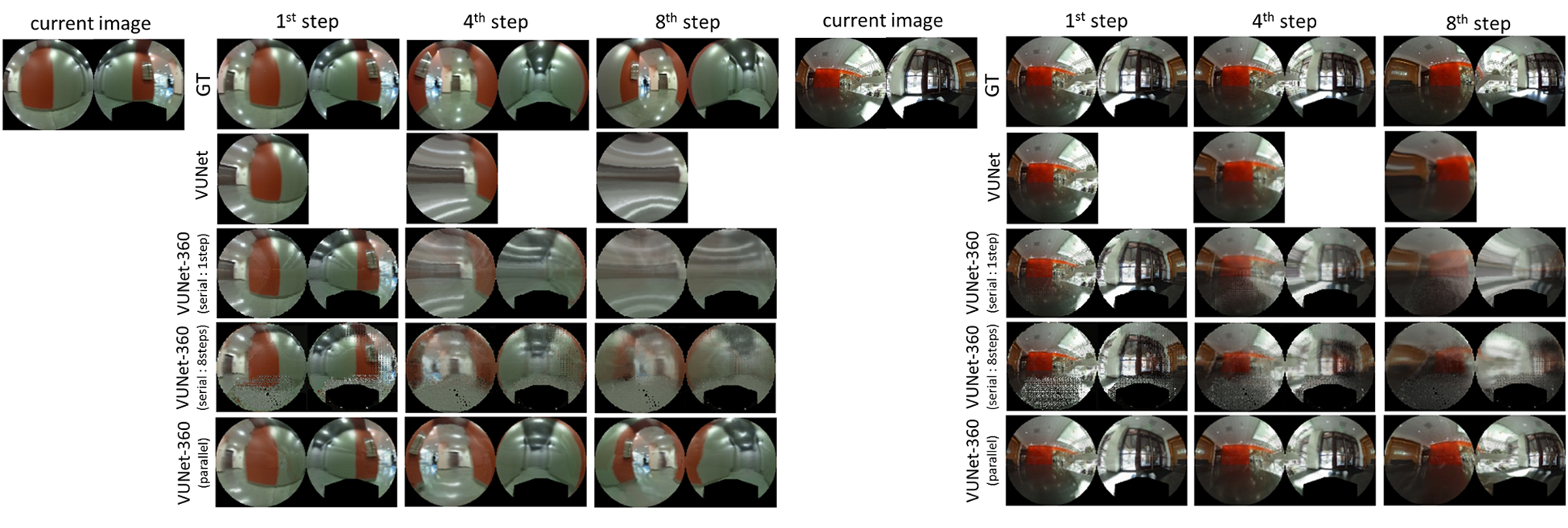
This figure shows groud truth(GT) image, predicted images by VUNet, and predicted images by VUNet-360 from 1st step to 8th step to verify our proposed predictive model, VUNet-360. Although the predicted images by original VUNet is very blur especially for far future, VUNet-360 can predict better images by blending front and back side view of 360 degree camera.

Next figure shows the comparison between GT images, predicted images by VUNet, predicted images by VUNet-360 with serial process, and predicted images by VUNet-360 with parallel process(our method). Our method, VUNet-360 with parallel process can predict multiple images by calculating only one encoder-decoder network. On the other hand, VUNet-360 with serial process predicts next image from current image and virtual velocities. Hence, we need to calculate the network multiple times for multiple step prediction. In addition, we train VUNet-360 with serial process by two different cost functions.(details are shown in arXiv paper.) From this figure, we can understand that VUNet-360 with parallel process can predict better images than VUNet-360 with serial process. Because, parallel process can use the raw current image to predict the images for 8 steps. On the other hand, VUNet-360 with serial process needs to receive not only raw image but also predicted image at each steps.
Following figure is for the additional evaluation of PoliNet. In the original manuscript, we only show current image, subgoal image, and the predicted image at 8th step. In the appendix, we are showing all predicted images. We can understand how our method tries to control the robot in virtual space.

Quantitative results
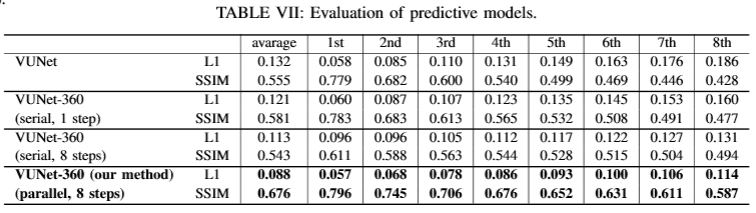
This table shows quantitative results of VUNet. We measure L1 and SSIM for 8000 images, which are randomly chosen from test dataset. As you can see, our method, VUNet-360 with parallel process can achieve smaller L1 norm and larger SSIM for all predicted images.
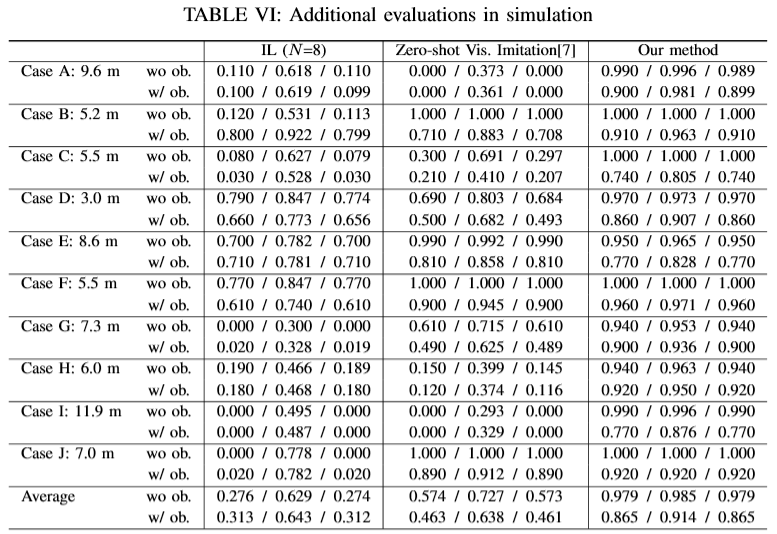
To verify that the results are statistically significant, we further evaluated our method compared to the strongest baseline, Imitation Learning(IL)(N=8) and Zero-shot Visual Imitation(ZVI), in seven additional random environments, and each 100 additional random runs.
The results of the seven new environments and the three previous environments in Table II of the original manuscript are shown in the next table.
Our proposed method can work well in all environments and outperforms all baseline methods.
Analysis of failure case
Although the baseline methods work well in each papers, the baseline methods often make mistakes in simulation of Table II. As the results, there are big gap between our proposed method and the baseline methods. In appendix, we explain the reasons for failures of each baselines.
Backpropagation
We think that there are three main reasons for the very low performance:
(a) In order to have a fair comparison we impose the same computational constraints on all algorithms: that they can be executed timely on real robot at, at least, 3 Hz. Conditioned on this constraint, the number of iterations in the backpropagation baseline is not enough to find a good velocity.
(b) The backpropagation method cannot use the reference loss. Therefore, the generated velocities are occasionally non-smooth and non-realistic and motivates some of the failures.
(c) As shown in Table I, first row, the computation time of the backpropagation method is enough to run at 3 Hz. However, this time introduces a delay between the moment the sensor signals are obtained and the velocity commands are sent that deteriorates the control performance.
Stochastic Optimization
The causes of this low performance are the same as for the previous baseline. Additionally, the predictive and control horizon of Chelsea's method is only three steps into the future, which is smaller than our predictive horizon of eight steps. This number of steps into the future is sufficient for the manipulation task of the original paper but seems too short for the navigation with obstacle avoidance.
Open Loop
In the 100 trials, we randomly change the initial robot pose and slip ratio. These uncertainties definitely deteriorate the performance of open loop control.
Imitation learning (N=1, and N=8)
It is known that imitation learning and behavior cloning often accumulate errors that can lead to finally fail in the task. We can find a few cases, which the imitation learning can achieve the high success rate. However, the average is quite lower than our method. We think that our task is one of the inappropriate tasks for the imitation learning.
Zero-shot visual imitation(ZVI)
ZVI often collides both with and without obstacle because, different to ours, it does not penalize explicitly non-traversable area and because the prediction in the forward consistency loss comes always from the raw image at previous step, which may not be enough to deviate to avoid the obstacles.
Visual memory for path following(VMPF)
Although VMPF is better than the other baselines, their original code doesn't include the collision detection module for the evaluation. It means that we didn't stop the evaluation even if their method collides with the obstacles. And, it seems that their control input is too discrete to avoid the obstacle and navigate in narrow environment.