ObjectFolder
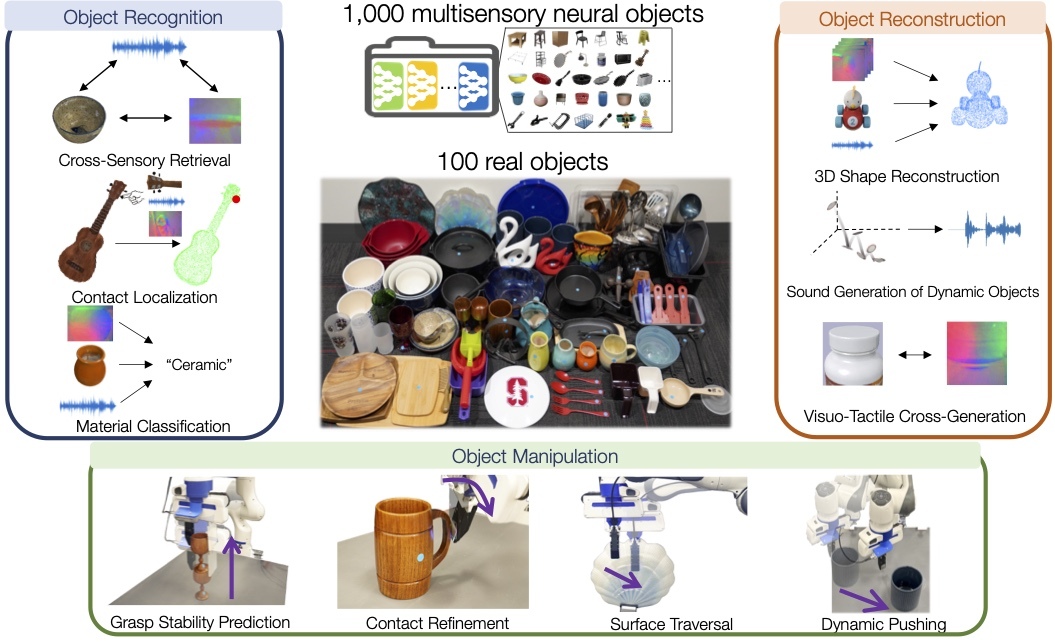
ObjectFolder models the multisensory behaviors of real objects with 1) ObjectFolder 2.0, a dataset of 1,000 neural objects in the form of implicit neural representations with simulated multisensory data, and 2) ObjectFolder Real, a dataset that contains the multisensory measurements for 100 real-world household objects, building upon a newly designed pipeline for collecting the 3D meshes, videos, impact sounds, and tactile readings of real-world objects. It also contains a standard benchmark suite of 10 tasks for multisensory object-centric learning, centered around object recognition, reconstruction, and manipulation with sight, sound, and touch. We open source both datasets and the benchmark suite to catalyze and enable new research in multisensory object-centric learning in computer vision, robotics, and beyond.
Link 













{kind=link}